
Objective
Install Splunk Enterprise on an AWS EC2 instance and examine data collected from my personal website, Phishy.Cloud
Introduction
The goal was to gain experience with Splunk by analyzing data from the personal website. Splunk was installed on an AWS EC2 instance, and the web interface was used to upload and examine the data for interesting findings.
Tools & Technologies Used
AWS EC2, Splunk Enterprise (SIEM), SSH, Bash, Google Analytics
Implementation
1. Create an AWS EC2 Instance:
Generate a new key pair and launch a suitable EC2 instance with at least 16 virtual cores and 32 GB or more of memory.
2. Connect to the Instance using SSH:
Use SSH to connect to the launched EC2 instance with the generated key pair. Create a free Splunk account, download Splunk Enterprise for Linux using wget, and install it.
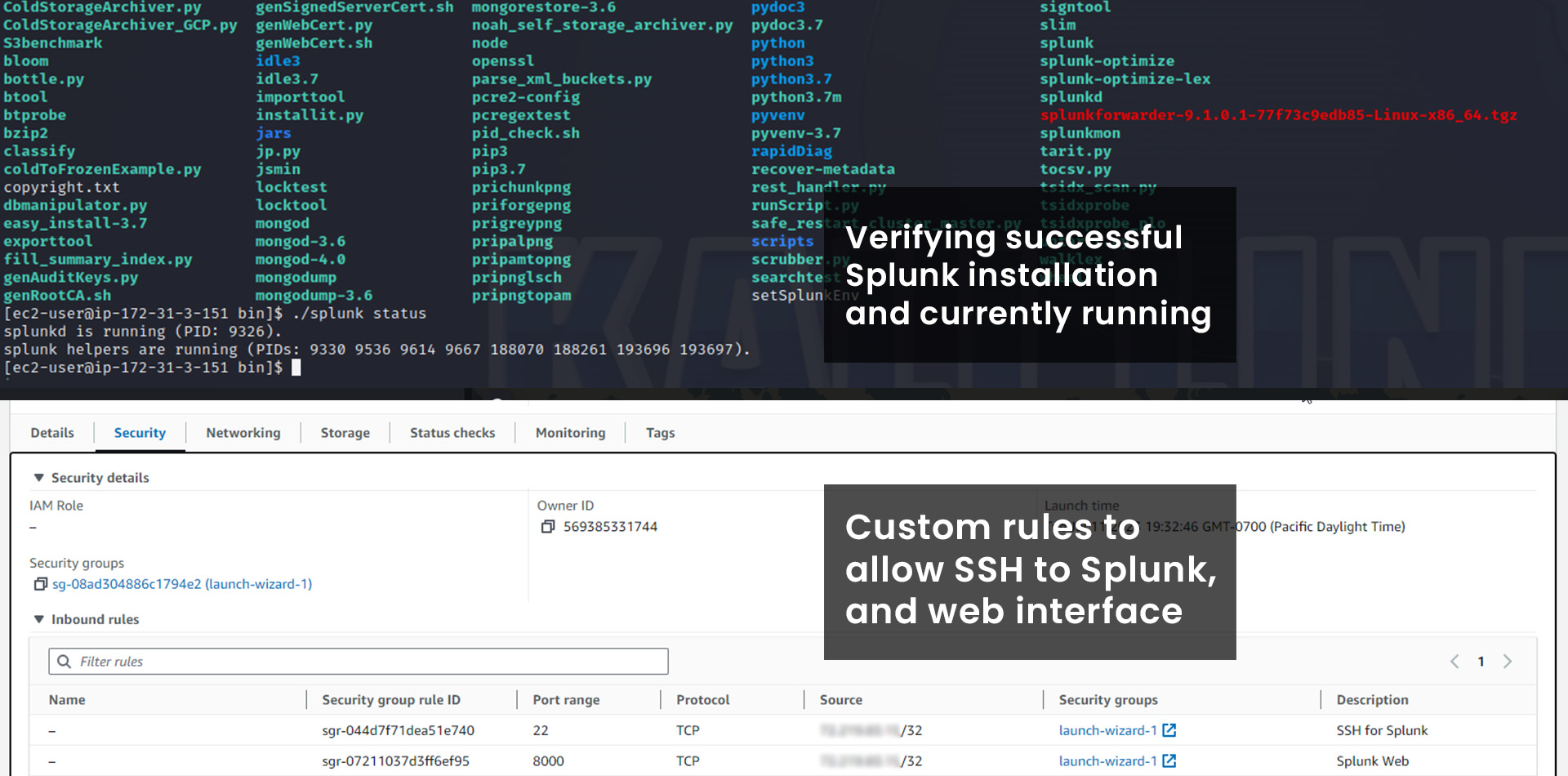
3. Install Splunk Enterprise:
Create a directory (mkdir) for Splunk installation. Extract the downloaded Splunk installation files using the command "tar -xzvC /opt -f filename.tgz". Complete the installation by running "./splunk status" and start Splunk with "./splunk start"
4. Update the Security Groups in EC2:
In the EC2 console, update the security group by adding an inbound rule allowing your IP to access port 8000 for the Splunk web interface.
5. Download Google Analytics Log Data:
Log in to the Google Analytics account and download a CSV file containing the complete history and data.
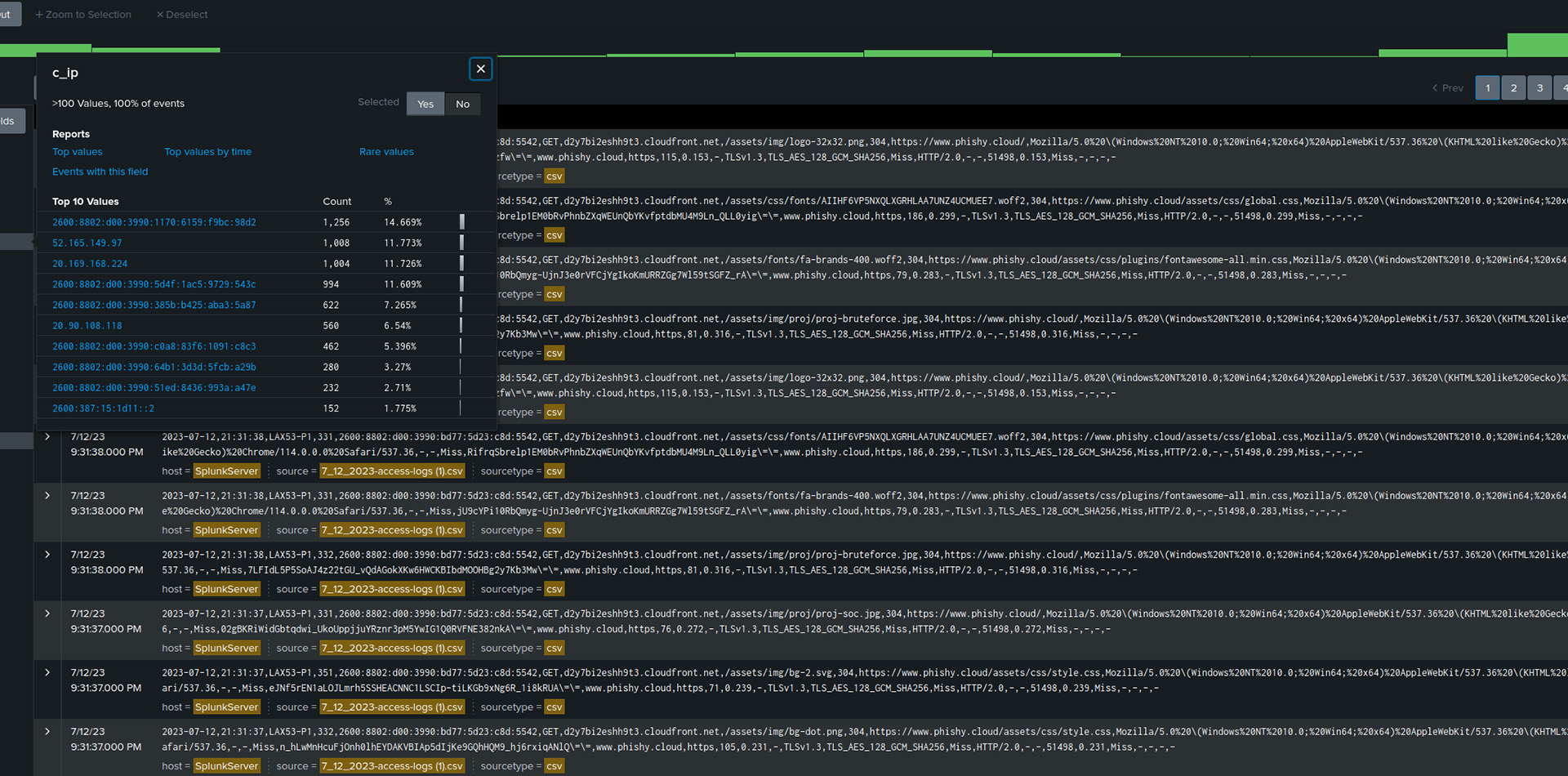
6. Upload and examine data in Splunk:
Log in to the Splunk web interface and upload the downloaded CSV data for viewing and examination.
Challenges & Lessons Learned
I had a big challenge when trying to directly connect AWS Amplify website log data to Splunk. Some features mentioned in the Amplify documentation were not available, possibly due to using the free tier.
Connecting live data directly to Splunk on AWS is still something I want to do, but I think I will save it for a different type of app that is hosted on S3 or EC2. Then I can utilize Splunk Universal Forwarder or something else to faciliate the connection and examine different types of live data sets.
Conclusion
Examining the website data on Splunk provided insights into numerous requests made to AWS and Microsoft servers. The requests to Microsoft were likely due to GitHub, as the website automatically synced with the GitHub repository. The overall experience was valuable, and it has piqued my interest in working on more data and exploring projects that involve a constant connection between Splunk and live project data.